브라우저에 URL을 입력하면 일어나는 일 - 기본 CS 지식
브라우저에 URL을 입력하면 크게 2가지 일이 일어난다. 1) 브라우저에서 파일을 가져오고, 가져온 파일을 브라우저에서 렌더링 한다. 우선 1) 브라우저에서 파일을 가져오는 과정부터 OS와 메모리와 연결지어 확인해보자.
하드웨어 종류
1. CPU: GPU에 비해 좀 더 커다랗고 복잡한 일을 처리하는 유닛(크기가 크고, 개수가 적다)
- Core: 각종 연산을 수행하는 핵심 요소, 스레드 단위로 Core 단위에 맵핑
2. Memory(ROM, RAM): 기억 장치.
3. 연산장치
4. Control Unit
5. GPU : CPU에 비해 작은 프로세싱 유닛들이 여러 개가 있어서, 단순반복 작업을 병렬적으로 처리함. => 단순 작업 처리가 쉬워서 그래픽 용으로 사용되었다 => 요즘은 GPU가 그래픽 뿐 아니라 단순 작업을 처리하는 다양한 곳에 쓰임
이러한 GPU, CPU 기반의 하드웨어 위에서 OS가 돌아가고, 이 위에서 Application이라 불리는 응용 프로그램이 돌아가게 된다. 브라우저 또한 이 응용 프로그램의 한 종류이다.
소프트웨어 종류
1. 프로그램: 실행 가능한 파일(코드로 이루어짐)
- statement: 실행 가능한 독립적인 코드 조각
-- expression : 계산하여 값을 만드는 코드
-- keyword: 명령어
- identifier: 값의 위치
2. OS: 운영체제(하드웨어를 제어하고 응용 프로그램을 실행하는 기본 프로그램)
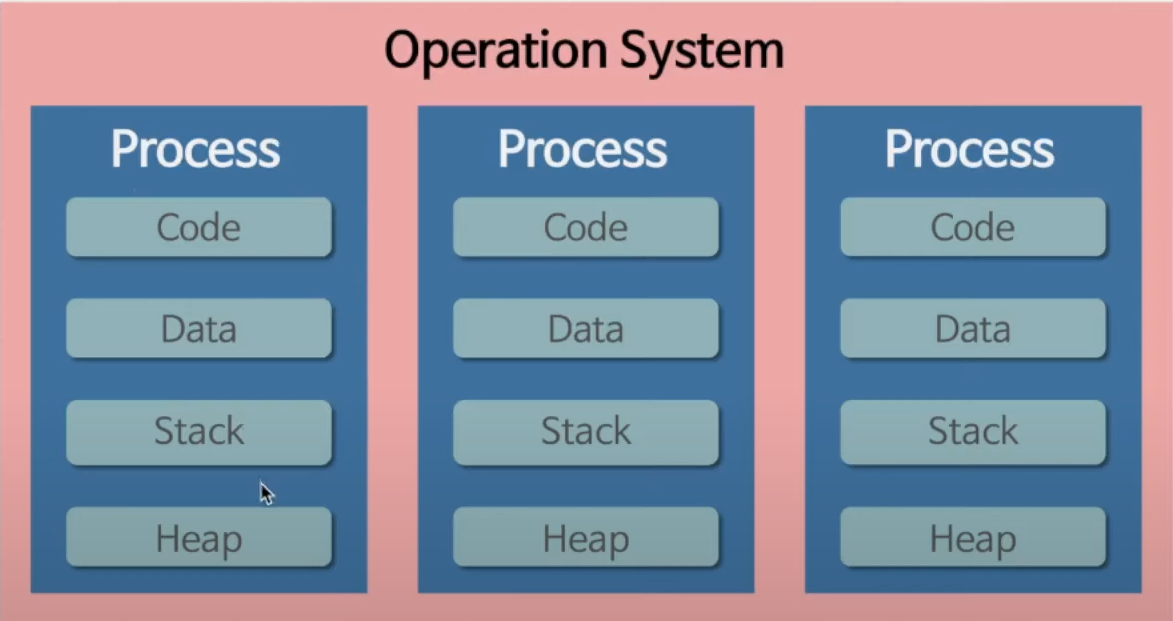
3. Process: 프로그램이 OS에 의해 memory 영역을 할당 받고 실행중인 것
하나의 프로세스는 4가지 요소로 이루어져있다.
- Code: PC(다음번에 실행될 명령어의 주소를 갖고 있는 레지스터, 코드를 저장)
- Data: global variables, static, variables 저장
- Heap: 메모리 관리, 동적 메모리 할당
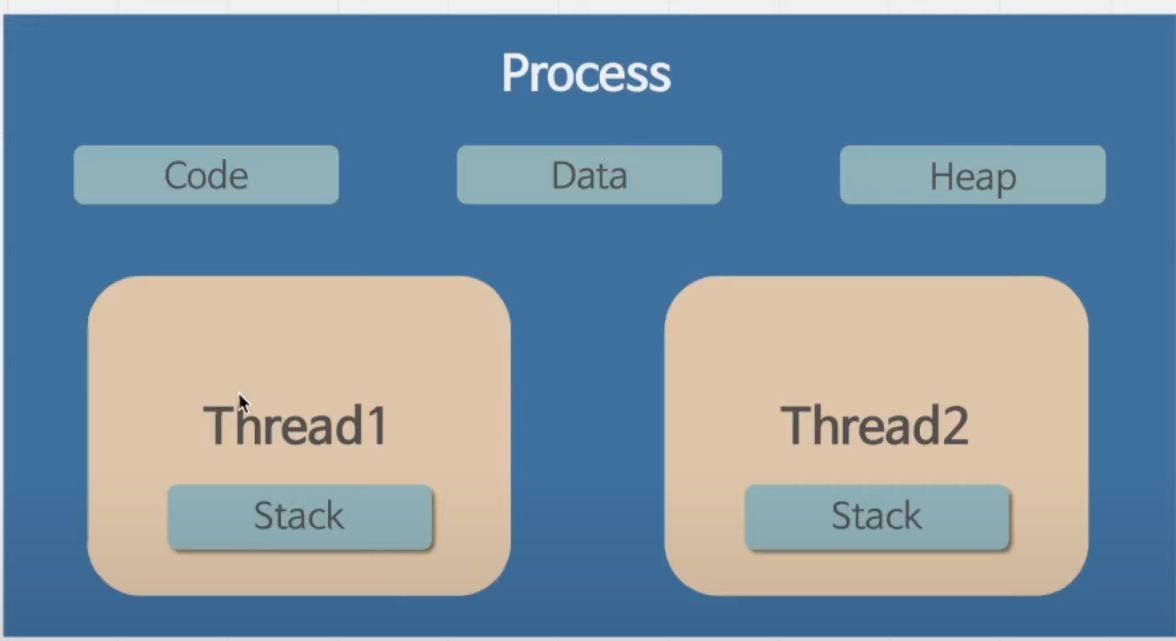
- Stack(Thread): 스레드는 명령어가 실행되는 흐름이라고 이해해야 한다. 스레드 내의 명령어들이 스택의 자료구조로 쌓이게 된다. 즉 스택은 스레드라는 추상 개념의 구현체라고 보면 된다.
멀티 프로세스 브라우저의 아키텍쳐
멀티 프로세스란? 브라우저 상에서 OS에 메모리를 할당받아 실행 중인 프로그램이 여러 개인 상태.
이 멀티 프로세스는 각각 다른 메모리 영역을 할당받았기 때문에, 이 두 프로세스 간 데이터를 주고받거나 실행 흐름을 주고 받으려면(=소통하려면) IPC(Inter Process Communication)이 필요하다.
프로세스 내의 스레드가 1개 있는 경우는 싱글 스레드, 스레드가 여러개일 경우 멀티 스레드라고 한다.
JavaScript는 하나의 실행 흐름을 가지는 싱글 스레드 언어이나, 멀티 스레드처럼 느껴지는 이유는 자바 스크립트가 비동기적으로 작업을 처리하기 때문에 여러개의 작업을 처리하는 것처럼 느껴지는 것이다.
CPU 내의 1개의 코어가 1개의 스레드와 연결(맵핑)된다. CPU도 코어가 1개 있을 경우 싱글코어 processor, 코어가 여러개일 경우 multi core processor이라고 부른다.
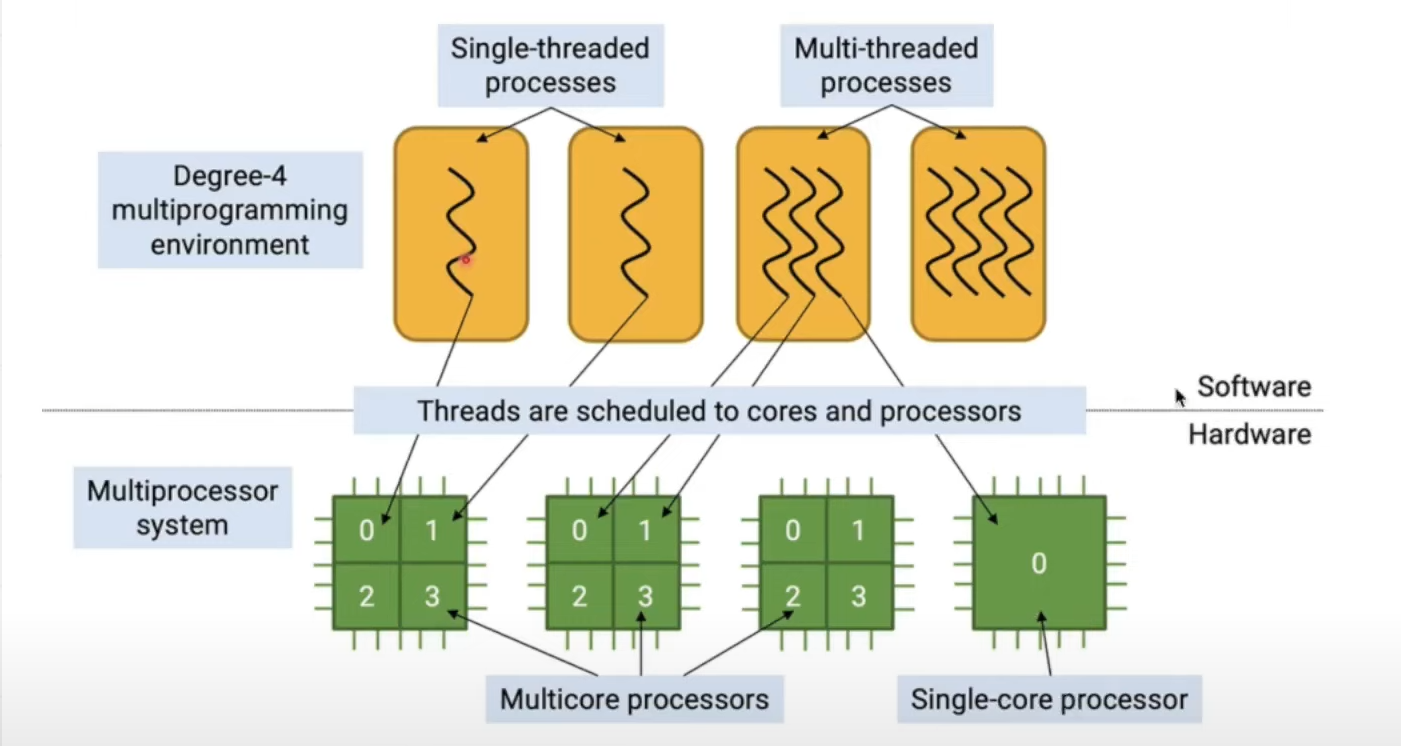
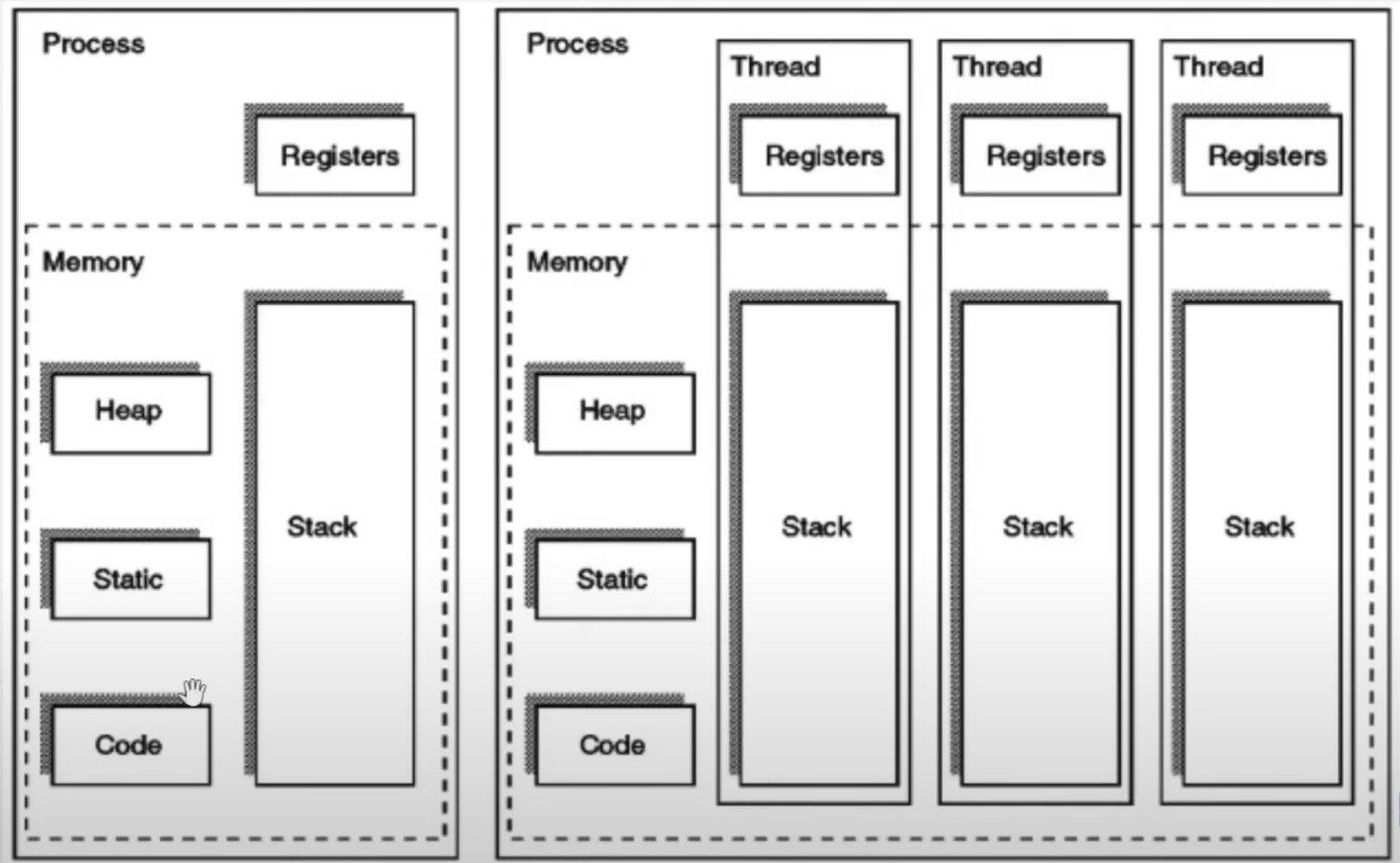
아래 그림을 보면, 왼쪽이 싱글 스레드 프로세스, 오른쪽이 멀티 스레드 프로세스이다. 둘의 공통점은 메모리 영역이 하나라는 것이다. 한 프로세스에는 하나의 메모리 영역이 할당되기 때문이다.
멀티 스레드 프로세스의 장점은 메모리를 공유하기 때문에 스레드 간의 필요한 데이터를 빠르게 공유할 수 있다는 점이다. 하지만 만약 서로 다른 프로세스 간 데이터를 공유하고자 한다면 IPC가 필요하다. 즉, 프로세스를 여러 개 띄우게 되면 메모리를 차지하는 비중이 늘어난다는 단점이 있지만, 서로 간의 메모리 영역에 접근하지 못하기 때문에 보안적인 면에서 장점이 있다. 이러한 장.단점이 있기 때문에 멀티 프로세스를 사용하게 될 때에는 멀티 스레드를 사용할지, 싱글 스레드 프로세스를 여러 개 사용할지를 고민해봐야 한다.
크롬 브라우저는 멀티 프로세스 아키텍쳐를 가진다.(각 브라우저마다 프로세스 아키텍쳐가 조금씩 다르니 기회가 되면 살펴보자.) 이제부터 크롬 브라우저와 멀티 프로세스 아키텍쳐를 좀 더 깊이 알아보자.
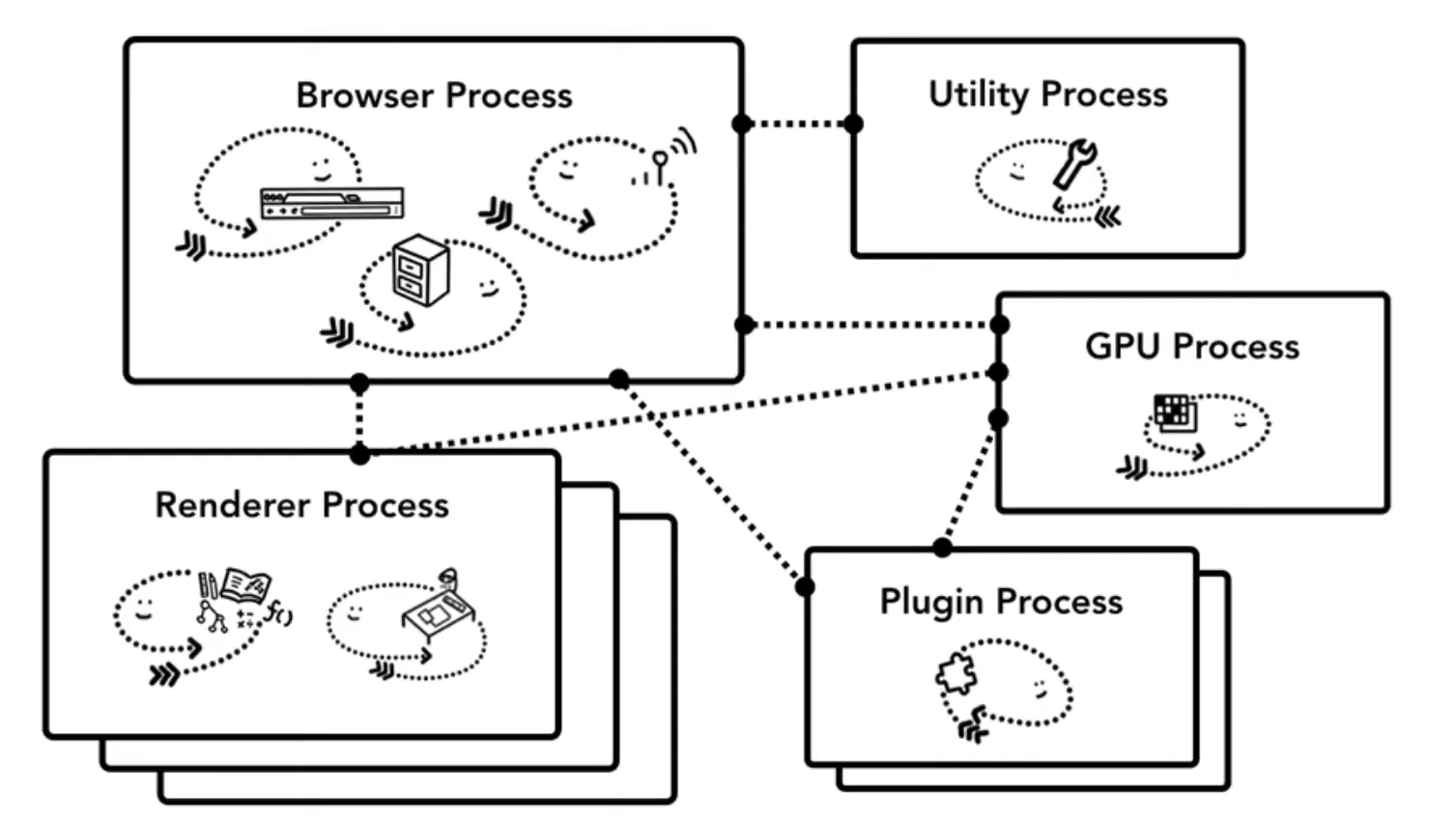
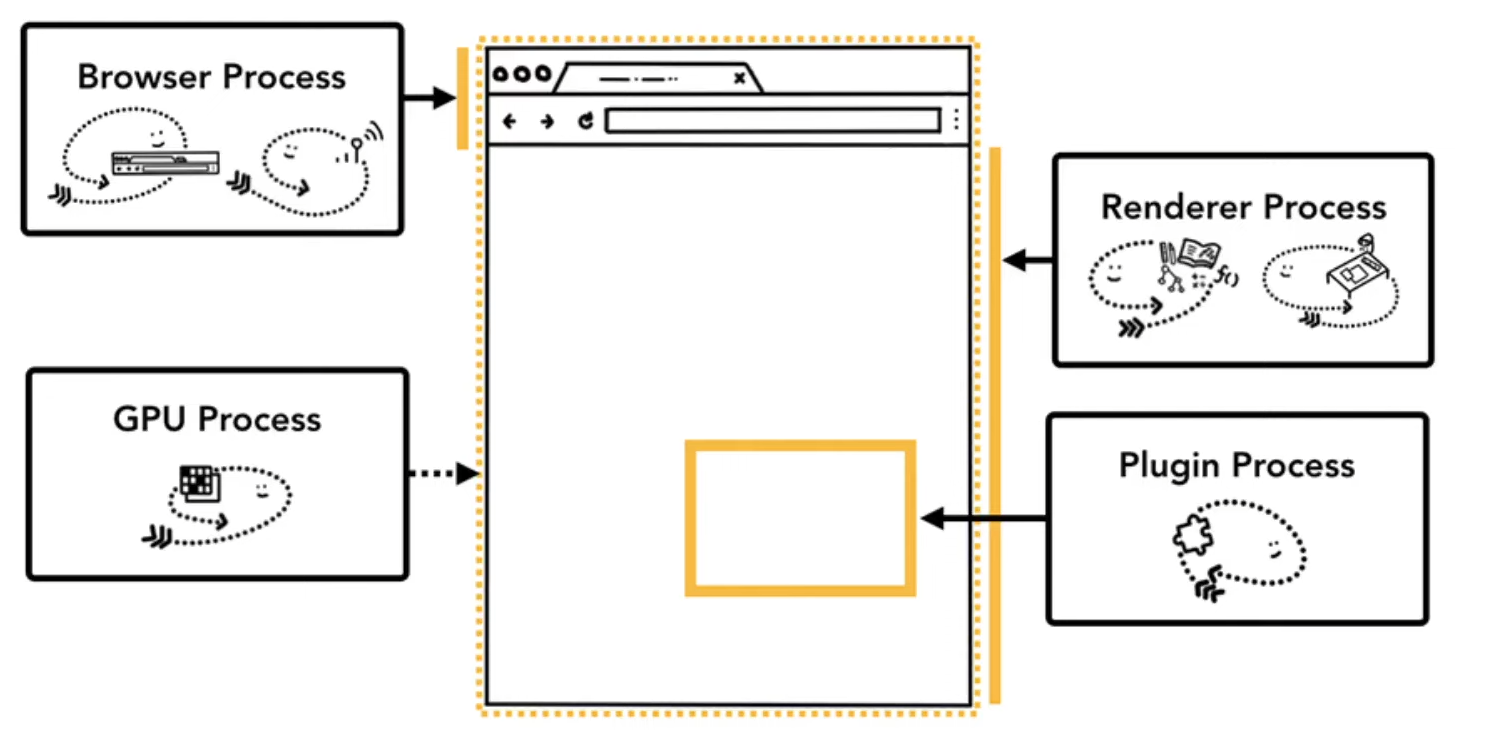
맨 상단의 새로고침, 주소 입력창 등 사용자 인터페이스 부분은 브라우저 프로세스가 담당하는 부분이다. 이 브라우저 프로세스 안에는 UI 스레드, 네트워크 스레드가 있다. 새로고침 등 버튼이 눌렸을 때의 동작은 UI 스레드가, url이 입력되었을 때 요청을 보내는 경우 네트워크 스레드가 작동한다.
렌더러 프로세스는 사용자가 보고 있는 브라우저의 한 화면을 만드는 역할을 한다. 즉, 브라우저 탭 하나 당 렌더러 프로세스 하나가 사용된다.(크롬 브라우저 특징)
플러그인 프로세스는 플러그인 한개 당으로 생성된다. 한 화면에 여러 개의 플러그인이 있을 수 있고, 따라서 여러 개의 플러그인 프로세스가 존재한다.
GPU 프로세스는 브라우저 프로세스와 렌더러 프로세스가 담당하는 전체 화면을 담당하는 것이다.
그럼 크롬 브라우저의 이러한 구성이 가지는 장점은 무엇일까?
1. 각 탭 당 1개의 렌더러 프로세스가 존재하기 때문에 하나의 탭에서 오류가 발생해 강제종료 시키더라도, 다른 탭에 영향을 미치지 않는다.(프로세스는 각각 메모리 공간을 할당받으므로 서로 영향 미치지 않기 때문에) 또한 보안에도 좋다.
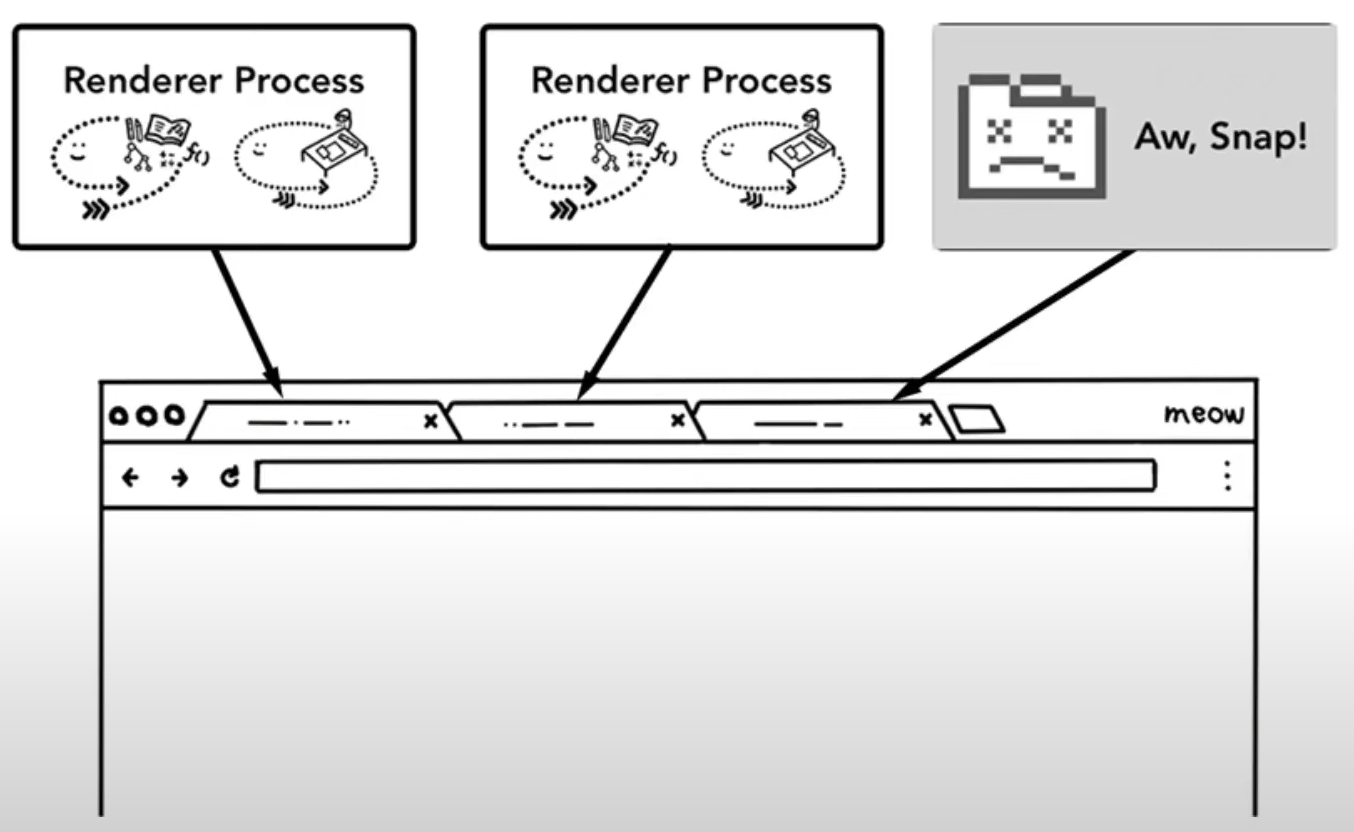
크롬 브라우저는 하나의 iframe 당 렌더러 프로세스 하나가 위치하는 정도까지 진화했다. 이를 통해 동일 출처 요청 외에 다른 요청은 받지 않는 등 보안적인 이슈를 해결하려 하고 있다.
크롬 브라우저는 메모리를 절약하기 위해, 메모리가 한계치에 달하면 서로 다른 렌더러 프로세스를 하나의 프로세스로 통합하여 하나의 메모리 영역을 할당하는 작업을 한다. 즉, 크롬 브라우저는 실행중인 환경에서의 cpu와 메모리를 계산해 한계치를 파악하고, 한계치일 경우 프로세스를 통합하는 것이다.
그렇다면 이런 크롬 브라우저에 URL을 입력하면 어떤 일이 일어나는지 알아보자.
1. handling inputs: 유저가 텍스트를 입력하면 시작되는 과정.
Browser Process 안의 UI Thread가 유저가 url 창에 text 입력한 것이 search query(검색어)인지 URL인지 판단
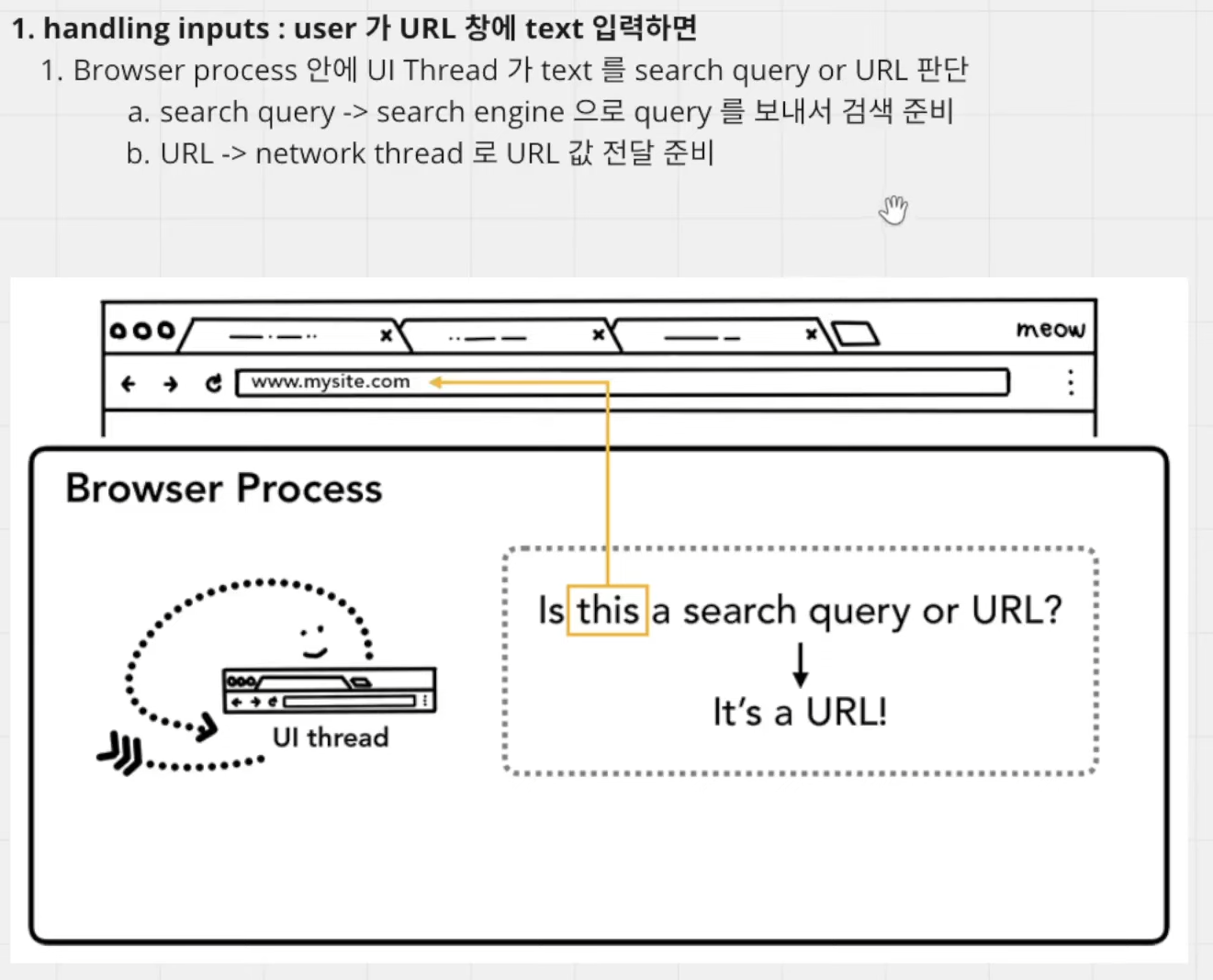
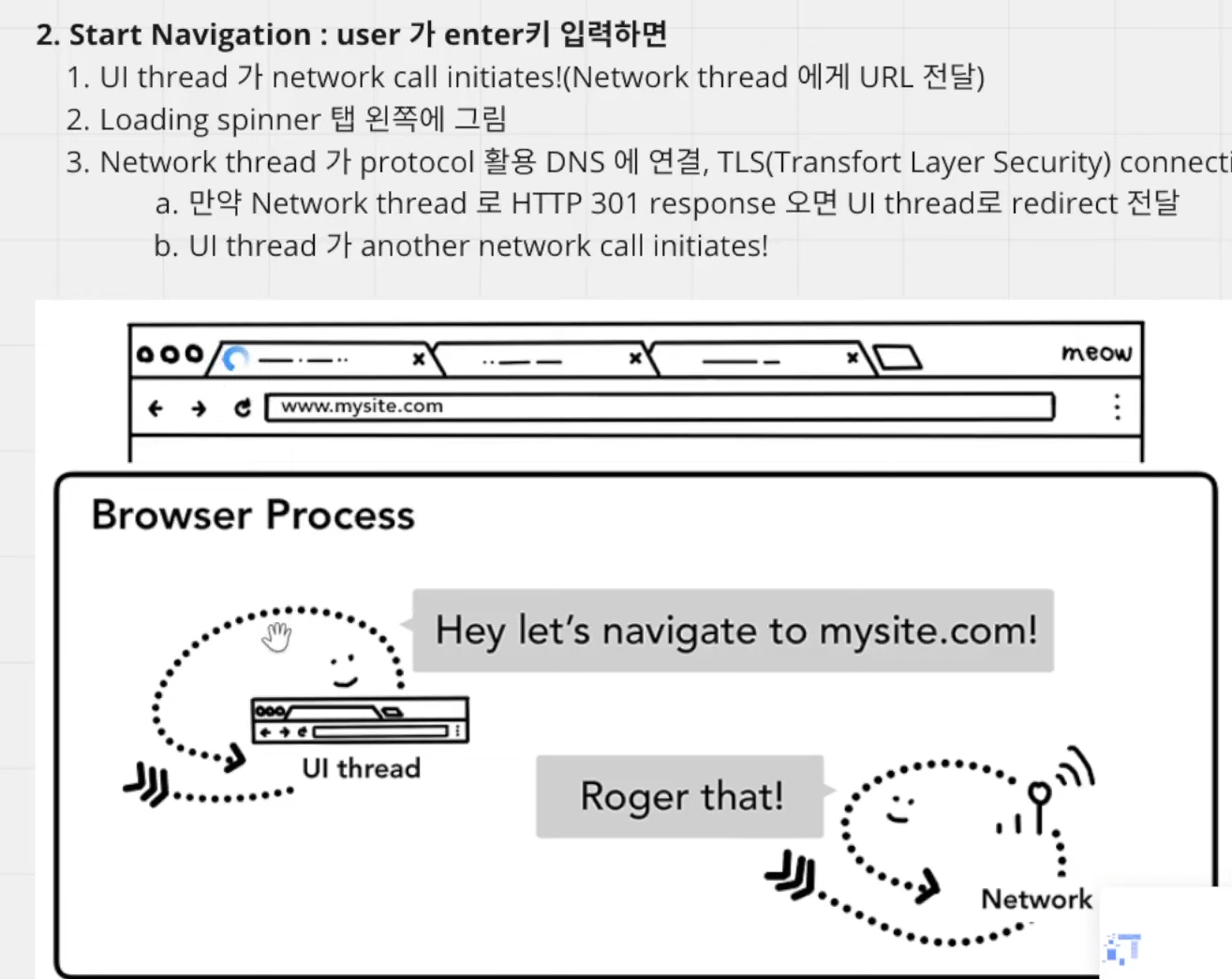
2. start Navigation: 유저가 엔터키를 치면 시작되는 과정.
1. UI 스레드가 네트워크 콜을 initiate 한다.(=Network thread에 URL을 전달한다.)
2. UI 스레드가 탭 왼쪽에 로딩 스피너를 띄운다.
3. 네트워크 스레드가 protocol 활용해 DNS에 연결하고, TLS 연결한다.(https는 http over TLS의 약자임.)
if 네트워크 스레드로 http 301 response(redirect) 오면 UI thread에 redirect 전달 => 다른 network call initiate 함.
else 301 response 아니면 다음 단계인 Read Response 단계 시작
3. Read Response: Response body가 Network thread로 들어올 때 진행되는 단계
0) 필요하면 Network thread가 response의 few bytes of stream을 읽는다(가령 2처럼 sniffing 할때).
1) response header의 content-type으로 type 확인한다.
2) type 더 자세히 알기 위해 MIME(Multi-purpose Internet Mail Extension) type sniffing을 한다.
이 것은 sniffing, 마치 냄새를 맡는 것처럼 respones body 에 들어온 few bytes of stream을 읽어서 content-type이 html인지, 아니면 다른 형식인지 파악한다.
3-1) content-type이 html 형식이면 renderer process에 파일 전달을 준비한다. 그런데 전달 전에 4와 5를 거쳐 안전성 검증을 한 후 전달한다.
3-2) content-type이 html 형식이 아니라 zip 등 다른 형식이면 : Download manager에게 파일 전달 준비
4) SafeBrowsing : 도메인이나 데이터가 malicious site인지 확인하고, warning page를 보여줌. (참고: https://safebrowsing.google.com/)
5) CORB(Cross Origin Read Blocking): 민감한 cross-site data(다른 출처에서 오는 데이터)는 renderer process에 전달하지 않는다.
4. Find Renderer Process: network thread가 확인 끝낸 후, 브라우저가 사이트 이동해야 한다고 판단이 선 후 진행.
1) 네트워크 스레드가 데이터를 준비한 후 UI thread에 "data is ready" 메시지 전달한다.
2) UI 스레드가 Renderer process에 전달. - *이 때 Renderer process는 4단계에서 찾는 것이 아니라, 2단계 start Navigation 단계에서 UI 스레드가 Network call을 initiate할 때 찾게 된다. 왜냐면 서버에 접근하게 되면서 Network request 수백ms 걸리기 때문에, UI 스레드가 Network 스레드에 URL 전달 후 미리 renderer process 찾는 것이다.
2-1) 2, 3단계 거치며 data가 다 갖춰지면, 미리 찾은 renderer process도 준비 완료 된다.
2-2) 2, 3단계 진행중에 cross site로 redirect 되면, renderer process 아닌 다른 process도 필요해진다.

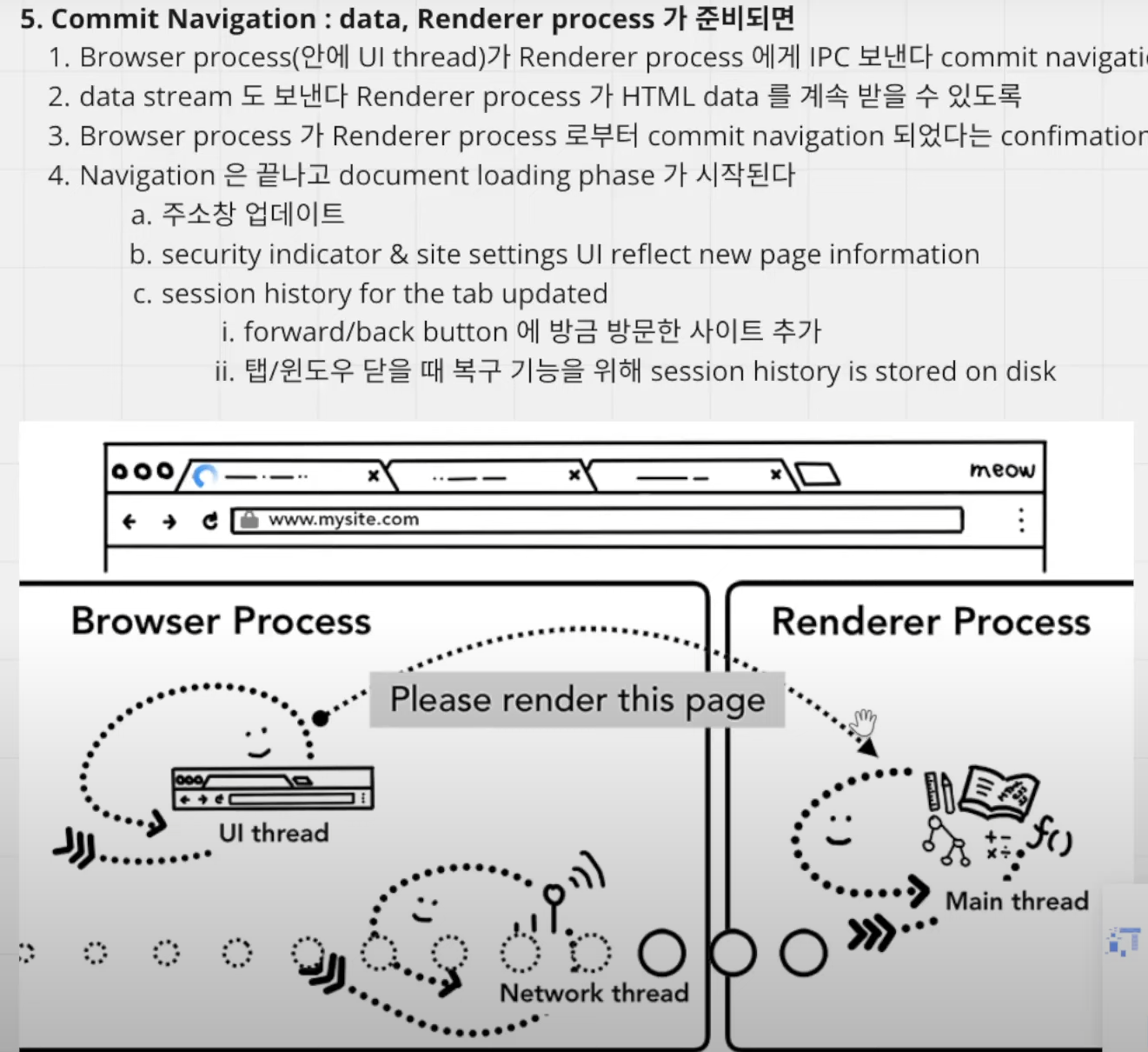
5. Commit Navigation: data, Renderer Process 준비되면 발생(=렌더링 준비 직전 발생.)
1. Browser process 안의 UI 스레드가 html 파일 데이터를 가지고 있다. 그래서 html 파일 데이터를 renderer process로 전달하는데 이 과정에서 IPC를 활용하게 된다.(서로 다른 프로세스이므로)
2. renderer process가 commit navigation 완료할 때까지 계속해서 data stream도 보낸다.
3. browser process가 renderer process로부터 commit navigation 된 confirmation 들으면
4. Navigation은 끝나고, document loading phase(본격적인 렌더링)이 시작된다. 이 단계에서 반드시 되어야 하는 것은 아래의 3가지이다.
4-1) 주소창 업데이트
4-2) security indicator와 site settings UI가 새로운 페이지 정보를 반영해야 한다.
4-3) session history가 탭의 업데이트 상황 반영해야 한다. => 그래야만 1) 뒤로가기/앞으로 가기 버튼에 방금 방문한 사이트가 추가되며, 2) 탭/윈도우 닫을 때 복구 기능을 위해 session history가 disk에 저장된다.
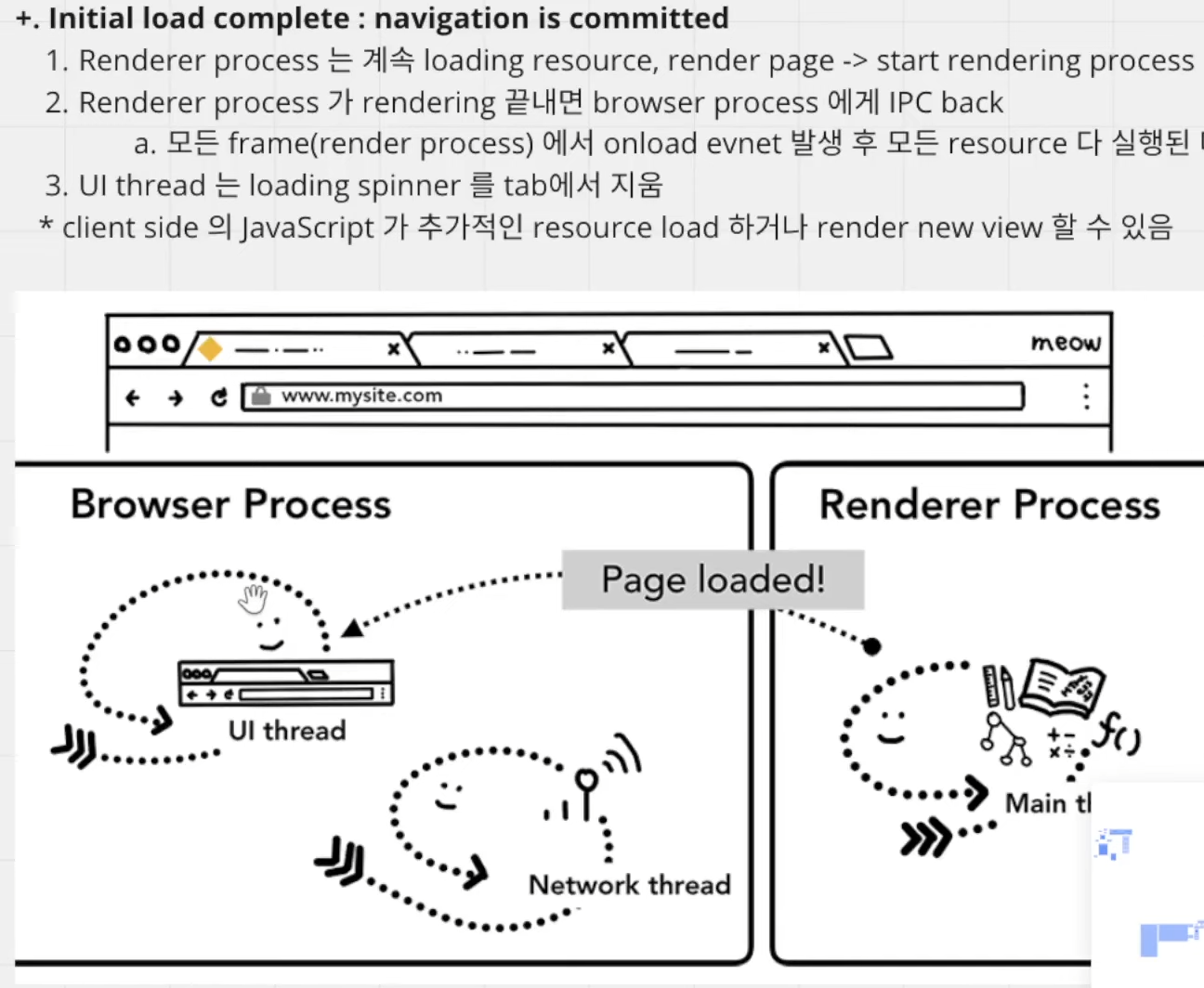
+. Initial load complete : 네비게이션이 완료된 이후에도..?!
1. Renderer process는 렌더링이 끝나기 전까지 계속해서 resource를 로딩해온다.
2. 그러다 모든 iframe에서 로딩(=렌더링)이 끝나면 renderer process는 browser process에 렌더링이 끝났다는 메시지를 IPC로 다시 전달한다.
3. UI 스레드가 loading spinner을 탭에서 지운다.
* 이 모든 과정이 끝나더라도, renderer process는 새로운 요청 들어와서 script 태그같은 것을 새로 로드하거나 할 수 있다(Ajax)
'개발 공부 > 웹 개발' 카테고리의 다른 글
| [TIL] 함수형 프로그래밍과 람다에 대해 (0) | 2022.12.13 |
|---|---|
| [가장 쉬운 웹개발 with Boaz] 브라우저 렌더링 최적화 (0) | 2022.12.13 |
| 브라우저 동작 원리 - 브라우저는 어떤 순서로 동작하는가? (0) | 2022.11.21 |
| [Git] GitHub Action 공부 (0) | 2022.08.23 |
| [Git] Git Dependabot Alerts 문제 해결 (0) | 2022.08.18 |